← Back to Work
Transfer
FINTECH OPERATIONS · AI-ASSISTED · MY FIRST PROJECT
Transfer
Desk
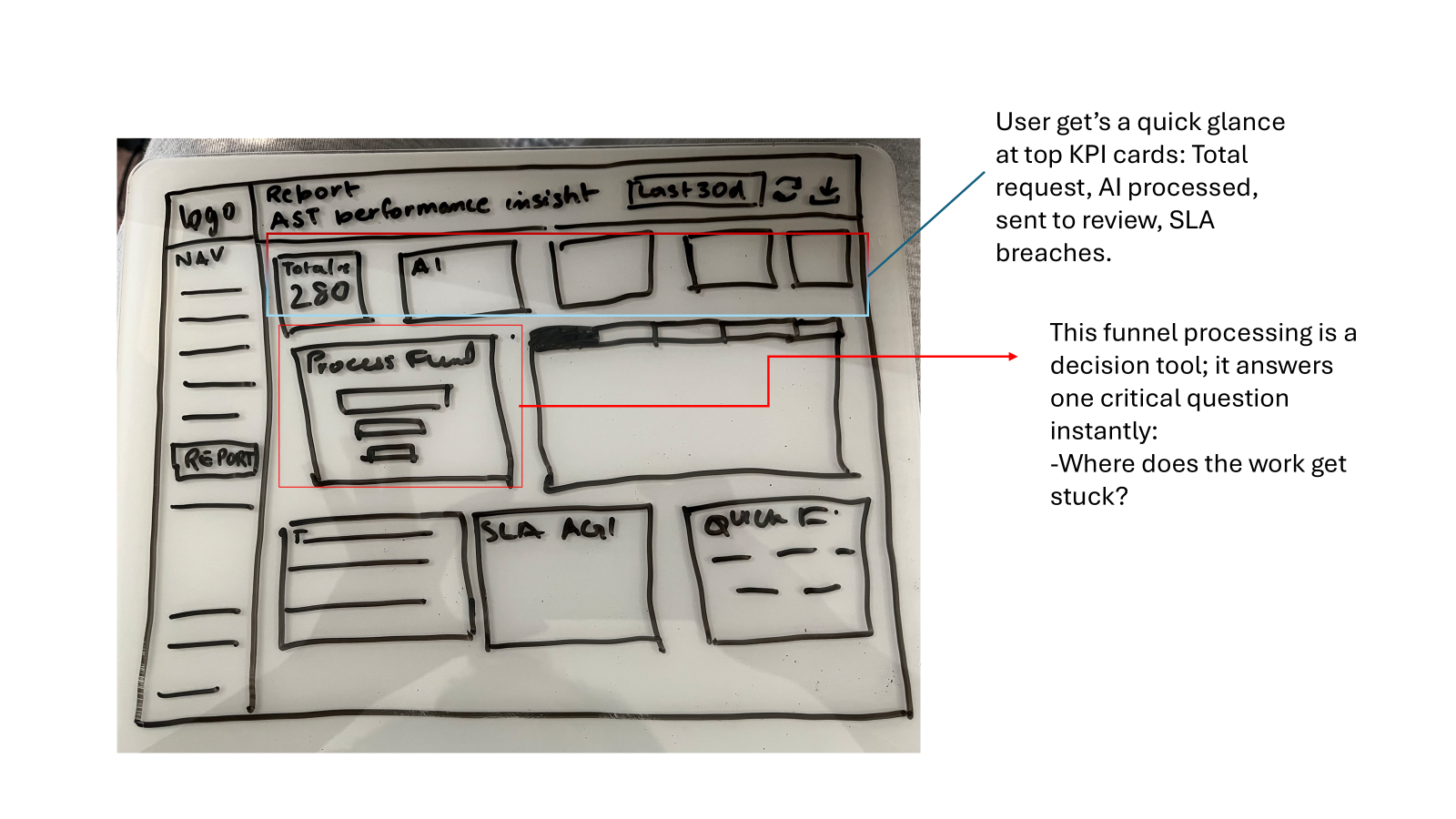
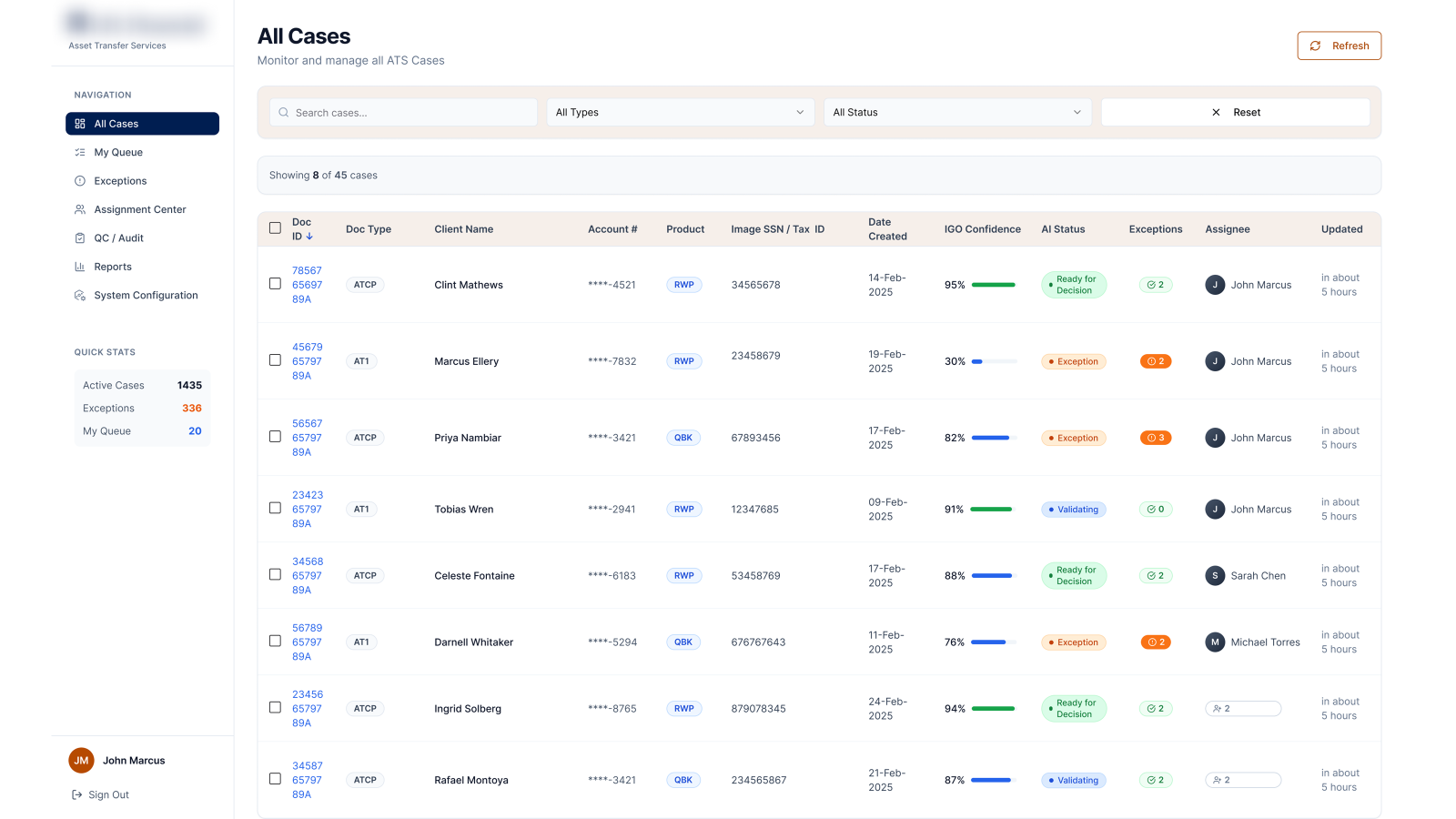
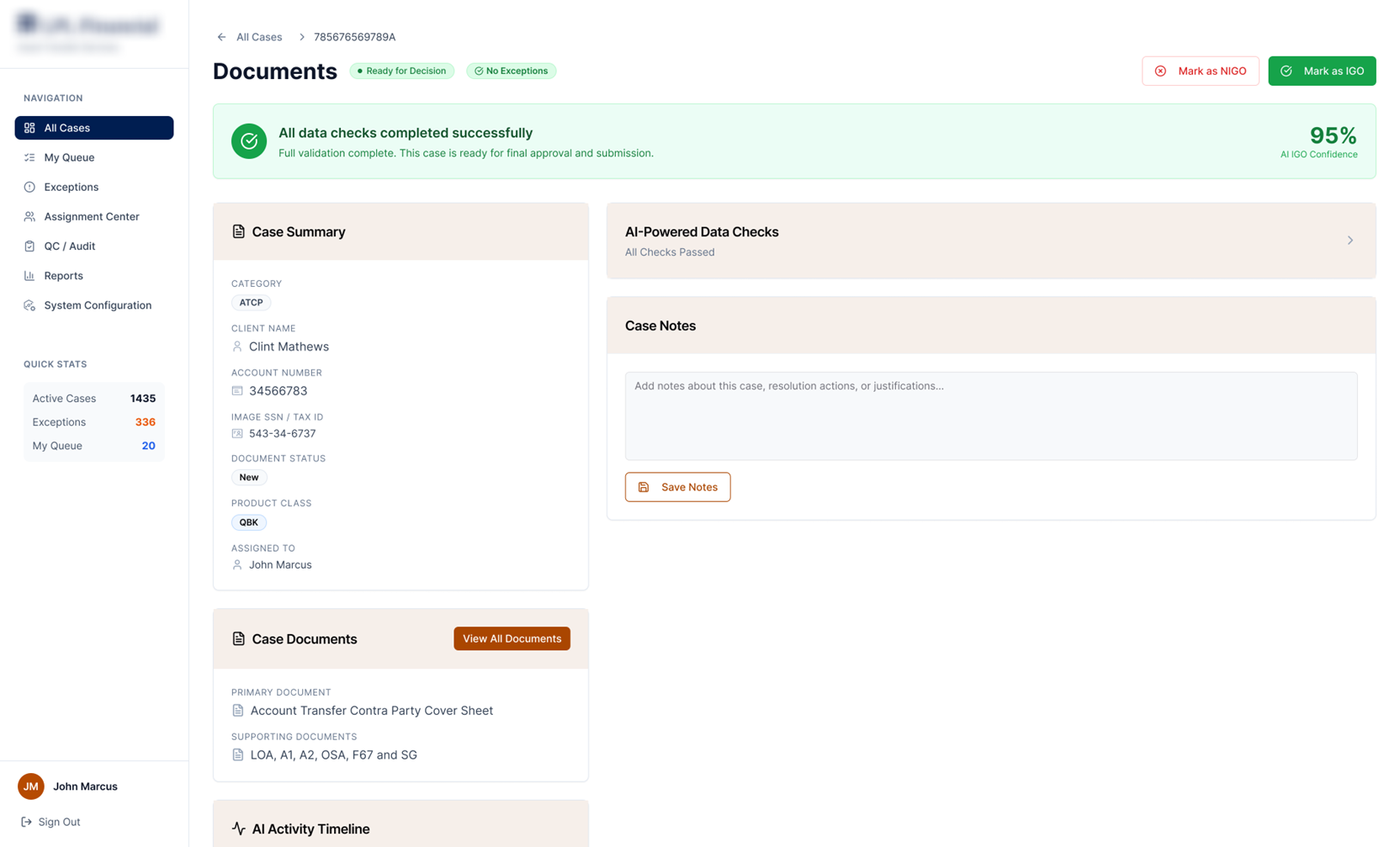
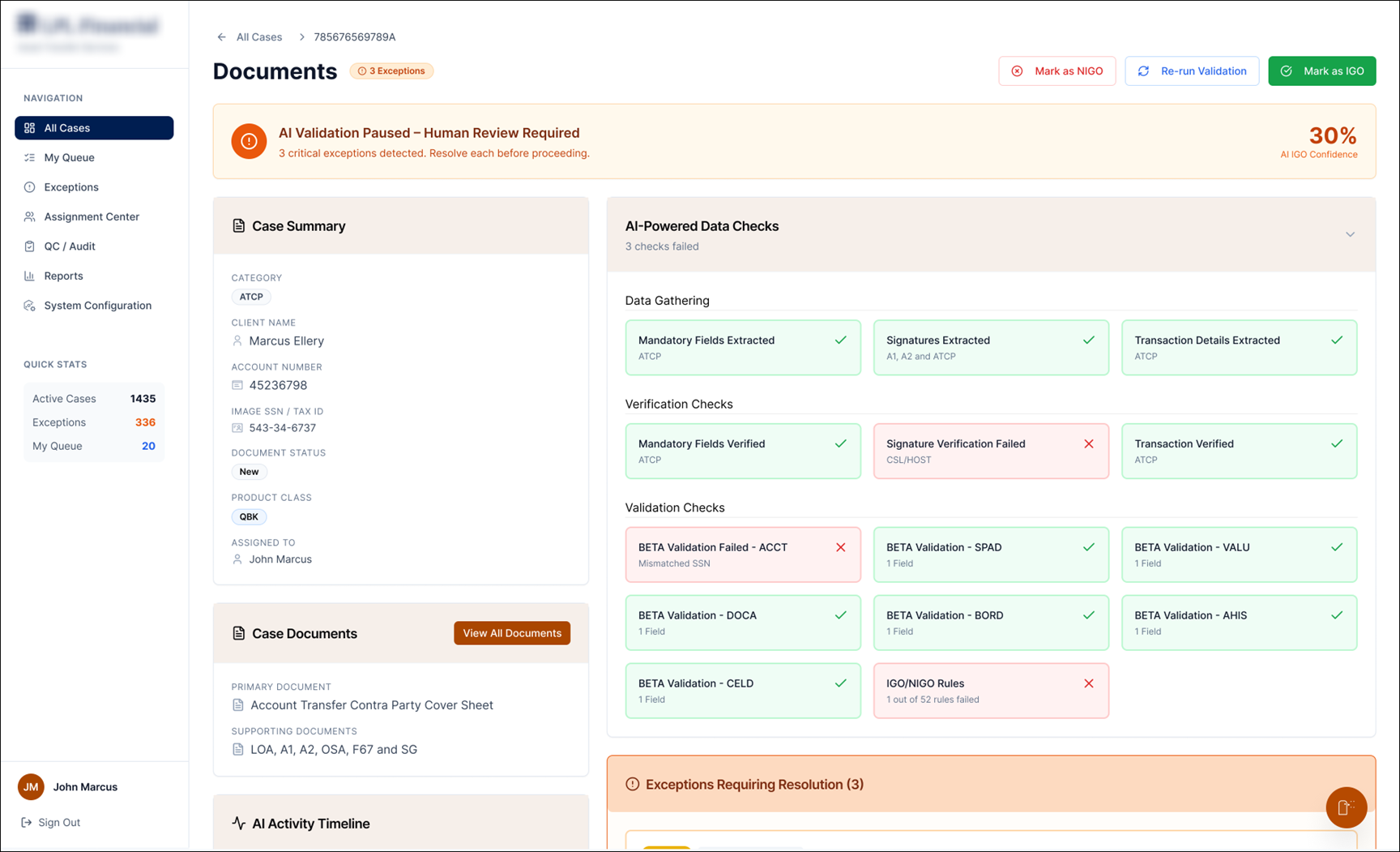
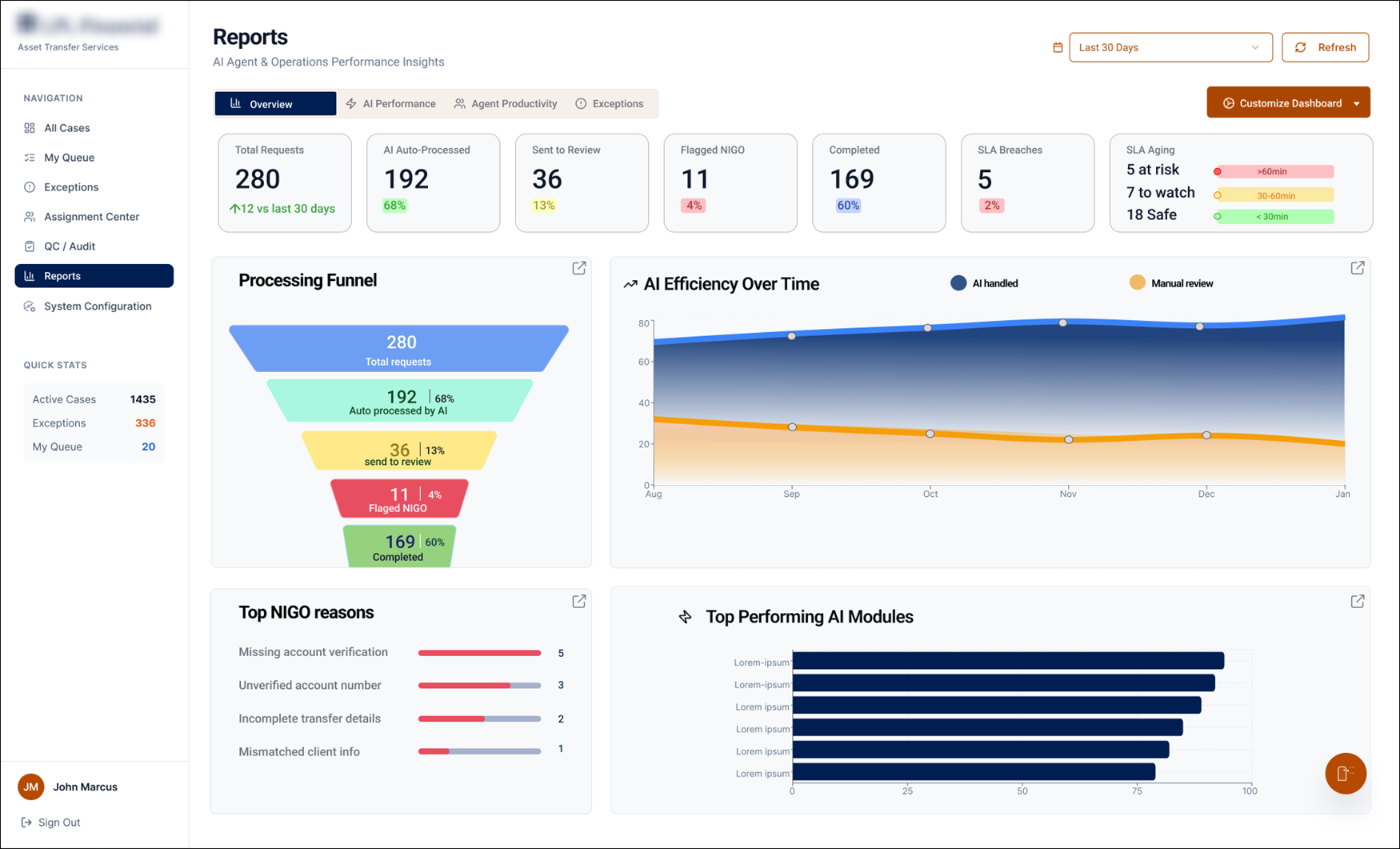
An AI-assisted operations console for asset-transfer teams — turning a wall of cases, checks and charts into clear, glanceable signals that show what's stuck, why it's flagged, and what to act on next.
The redesigned Reports tab — built so a manager reads the whole operation's health in seconds.